


• AWS, Azure, and Microsoft 365 faced widespread outages affecting tens of thousands globally.
• Microsoft confirmed portal and Outlook disruptions, while AWS has yet to issue a full statement.
• The repeated failures highlight the growing risk of cloud centralization and its global ripple effects.
Thousands of users faced major service interruptions on Amazon Web Services (AWS) and Microsoft platforms Wednesday, just a week after a similar outage caused widespread chaos across the internet. Reports from Downdetector showed sharp spikes in complaints for both tech giants, reigniting concerns about cloud reliability and centralized infrastructure risks.
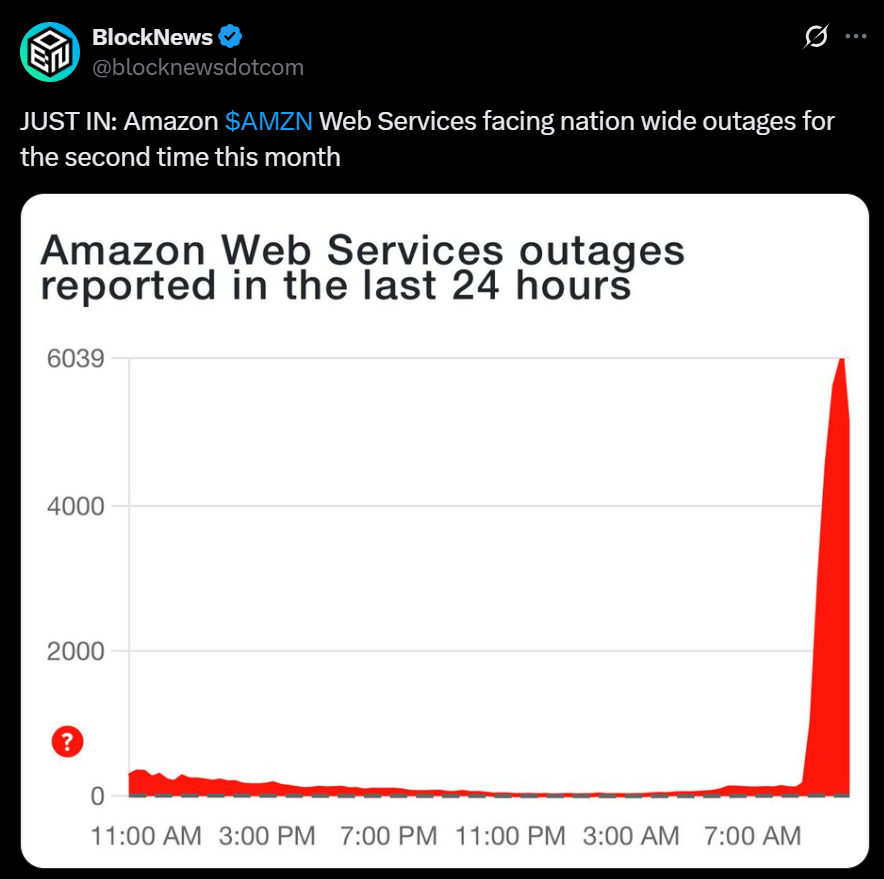
As of mid-morning, over 5,800 AWS users reported being affected, while Microsoft’s Azure logged more than 16,600 problem reports and Microsoft 365 nearly 9,000, according to data compiled by the monitoring site. Both companies have yet to confirm the root cause publicly, but the scale of disruption suggests another significant technical fault rippling through global servers.
Microsoft Confirms Portal and Outlook Problems
Microsoft issued brief updates acknowledging issues with the Azure Portal, warning that customers might struggle to log in or manage cloud resources. The company also noted that Microsoft 365 services — including Outlook and its admin center — were experiencing slow access times, add-in errors, and network connectivity issues.
These failures mirror last week’s outage, when similar disruptions took down key enterprise tools across continents. While engineers race to restore normal operations, users are already expressing frustration on social media over recurring reliability problems in platforms that power much of the digital economy.
AWS Faces More Scrutiny After Repeated Failures
For Amazon, this marks another blow after its US-East-1 Region suffered a critical failure last week, knocking out over 80 internal services and affecting countless third-party platforms — from banks and gaming networks to social media platforms dependent on AWS hosting.
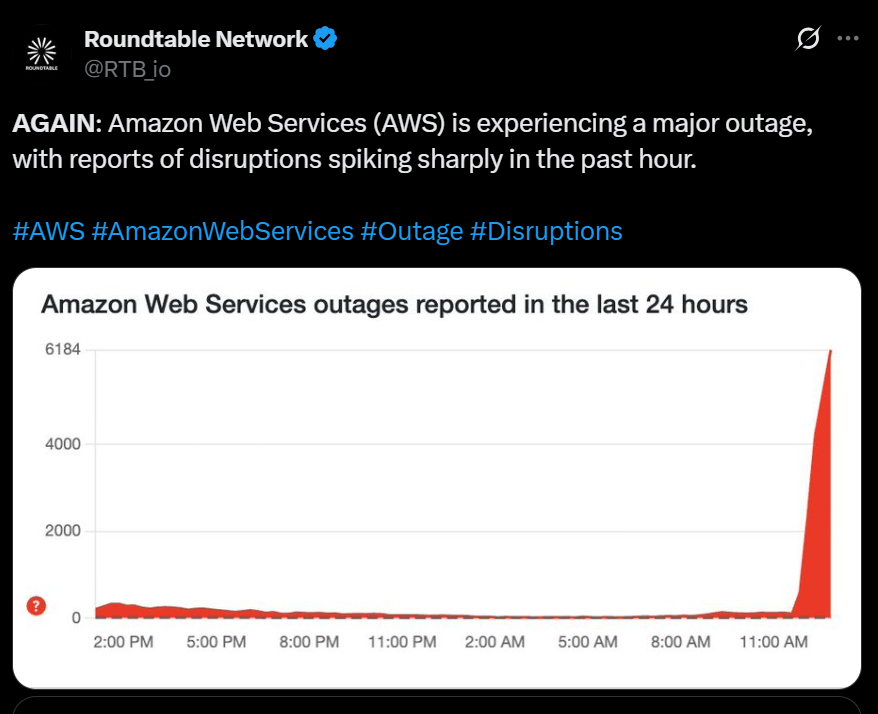
The region, located in Northern Virginia, is notorious for being the backbone of Amazon’s infrastructure. When it stumbles, large chunks of the internet often go dark. Experts are calling for greater redundancy measures and transparency about how cloud providers manage cascading failures across dependent systems.
The Bigger Picture: A Fragile Internet Backbone
The recent wave of outages has exposed just how fragile the global internet ecosystem remains, even as it grows more centralized around a few massive cloud providers. A glitch in one data center can now ripple through banking systems, streaming platforms, and enterprise software in seconds — an unsettling reminder of digital dependence.











